JavaFXアプリケーションのSceneGraphをScenicViewで確認する
これはJavaFX Advent Calendar 2014 15日目のエントリとなります。
昨日は@fukai_yasさんの「JavaFXでJavaとJavaScriptの連携」でした。
JavaFXで何か作っている時に表示が思い通りにならず、SceneGraphのツリー構造や各Nodeの状態を確認したくなることは多々あると思います。
で、ログを仕込んでアプリを起動して出力されたログを確認して、またログを仕込んで確認して、と面倒な作業の繰り返しになってしまうことも少なくありません。
そんな時、ScenicViewというツールでJavaFXアプリケーションを確認すると便利なので紹介します。
「ScenicView」とは?
JavaFXアプリケーションのシーングラフの構造やシーングラフ上のNodeのプロパティを確認することができるツールです。
またNodeのプロパティをツールから変更することも可能です。
ブラウザに付属しているデベロッパーツールみたいなものだと言えば分かりやすいでしょうか。
Oracleの JavaFX Third Party Tools and Utilities というページでも紹介されていますし、開発者はOracleのJavaFXの中の人なのでかなり有名なツールなんだと思います。
v8.0.0 が2014/9にリリースされておりJavaFX 8 のアプリケーションにも正式に対応しているようです。
このツール自身もJavaFXで開発されておりソースはここで公開されています。
起動方法
公式サイトから ScenicView.jar をダウンロードします。
以下3つの起動方法があります。
1. jarを実行
この方法が一番簡単なのでこれで良いと思います。
ScenicView.jarをダブルクリックするとJDKのホームディレクトリを聞かれるので設定するだけです。
あとはツールが起動するのでその後に対象のJavaFXアプリを起動すると自動で検知しSceneGraphが表示されます。
2. コードから呼び出す
ScenicView.show(scene);
ScenicView.jarにクラスパス通して上記コードを呼び出すだけ。引数には対象のNodeかSceneを渡せます。
試しにHTMLEditorを確認してみる
標準コンポーネントのHTMLEditorを表示するとこんな感じです。
左側にSceneGraph上のNodeのツリー構造、右側には選択したNodeのプロパティを確認することができます。
Nodeのプロパティはすべて確認できるようになっていますし、四角いアイコンがある項目はScenicViewから変更することも可能です。
対象のNodeが独自コンポーネントの場合でもpropertyメソッドがあればちゃんと項目として表示してくれます。

左側のツリーからNodeを選択するとアプリケーション上のコンポーネントをハイライトしてくれる機能もあります。

上とは逆にアプリケーション上のコンポーネントを選択するとツリー上のNodeを選択してくれる機能もあります。

使いどころ
- 開発時の表示の確認
FXMLを使用せずに動的にSceneGraphにNodeを追加したり削除したりするようなアプリケーションではツリー構造やNodeの状態が意図通りになっていないことがあったりするので確認に便利です。
また座標をゴニョゴニョしていたりする場合、慣れていないと大変だと思うのですが選択Node、Boundsのハイライトが参考になり理解を助けてくれると思います。
ただし全てのビューをSceneBuilderを使ってFXMLで表現できるようなアプリケーションであれば使用する必要はないかもしれません。
- 自分以外が開発したJavaFXアプリケーションの確認
リリース前の最新版の新機能を確認してみた
今後どのような機能が追加されるのか気になったのでリリース前の最新版を動かして確認してみたら面白い機能がありました。(便利な機能かどうかは別として)
ThreeDOMというタブが追加されているのでこれを選択するとシーングラフの構造を3Dで表現してくれるみたいです。面白いので画像貼っておきます。なんかすごい。。。

他にもCSSFXというタブも追加されてたりしたので今後の機能追加にも期待です。
JavaFXの開発をしていてまだScenicViewを使用されたことがない方は一度試してみてはいかがでしょうか?
明日は shunsuke.mori.393 さんです。
Jenkinsでビルド後に音(BGM、SE)を鳴らしてみた
Twitterでビルド後の通知にゲームのBGMを鳴らしてるという話を聞いたのでマネしてみたところ結構良かったのでメモ。
- 導入した理由
- 楽しそう
- 通知はメールやらIRCやらでやっていたけどなんとなく埋もれがち、気付かなかったりすることもあった
- ビルド後に音を鳴らしてみて
- そこに居れば絶対に気付くのは良い
- ビルド失敗音がなる度に失敗した理由をチームメンバと話すようになった。「あ、今の自分かも。調べますね。」みたいな。
- フィードバックがより早くなった
- ゲームみたいで楽しい
- 他チームの人も「何やってんの?」みたいな感じで Jenkins とか CI な開発に関心持ってくれる
- その他
- BGM、音はチームメンバで楽しく決めたい。趣味の合う合わないとか。
- 失敗音はなるべく軽いものを(継続的に鳴るので重いと辛くなっちゃう)
Jenkinsで音を鳴らすには
- プラグインのインストール
- Jenkins Sounds plugin をインストールします。
- プロジェクトの設定
- ビルド後の処理 の Jenkins Sound を選択します。
- 以下の設定項目が表示されるのでビルド結果に応じたサウンドを選択して設定。直前のビルド結果の設定もできるのは嬉しいです。

上の例は成功時には alleluia、失敗時には EXPLODE それぞれ異なるサウンドが鳴るように設定をしています。
選択できる音源は予めプラグインに同梱されているのでとりあえず選択しておけば音を鳴らすことができます。(どれも微妙ですが…)
これだけの設定でJenkinsサーバからビルド後の結果によって音を出すことができます。お手軽。簡単。
サウンドファイルをカスタマイズしたい場合
上記の設定で音を鳴らすことはできましたが、おそらく自由に音源を設定したくなるハズです。
Sound Plugin では当然設定できるようになっています。音源ファイルのzip作ってJenkinsの設定するだけです。
手順は以下の通り
- サウンドファイルの作成
- Jenkinsの設定
- Jenkinsの管理 > システムの設定 のリンクから設定画面を開く
- Jenkins Sounds の Sound archive location に 作成したzipファイルのパスを設定する(http://, file:// の表記で指定)
ちなみに自分のチームでは 成功時には某RPGのレベルアップの音、失敗時にはヒゲが死んだ時の音 を流しています。
ビルドの度に鳴りますし、短くて軽い雰囲気の音が良いかと思います。
JenkinsサーバではないPCから音を出したいケース
自分のプロジェクトではその辺に転がってたノートPCをJenkinsサーバにしたため、Jenkins自体のPCから音が鳴っても良い状態です。
以下のようにJenkinsサーバが開発チームのすぐ近くある場合は問題ありません。
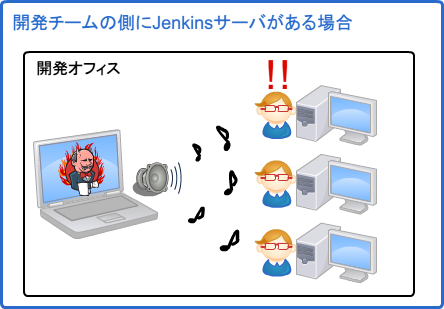
チームによってはJenkinsをどこか別の場所のサーバ上に立てることもあると思います。
以下のようにJenkinsサーバが開発チームのすぐ近くにない場合はJenkins自体から音が鳴っても気付くことはできません。
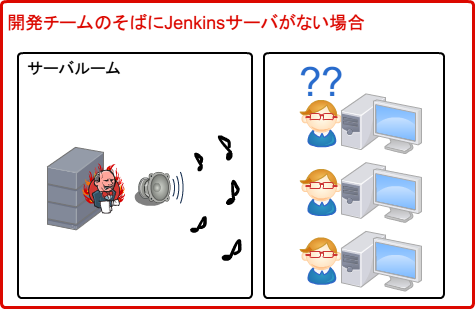
Sounds plugin はバージョン0.1がリリースされた当初はそこまで対応していなかったみたいですがバージョン0.4からは別のPCのブラウザ上から音を鳴らすことが可能になっています。素敵。
※かえる本でも Sounds plugin は紹介されていたのですがまだ対応される前だったのか触れられていませんでした。
以下のように音が出るPCを開発チームの側においてブラウザを上げておくだけで音でビルド結果を通知することができます。
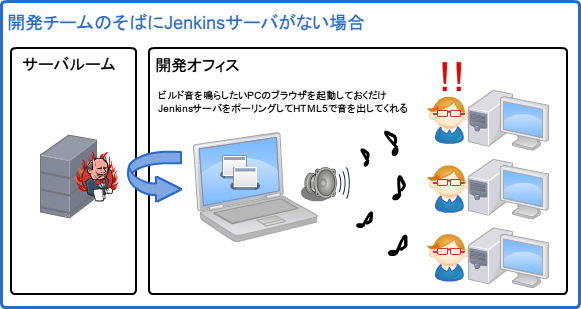
以下手順
- Jenkinsの設定
- Jenkinsの管理 > システムの設定 のリンクから設定画面を開く
- Jenkins Sounds の Play through HTML5 Audio enabled browser.にチェック
- 音を鳴らすPCの準備
- ブラウザを立ちあげて http://Jenkinsサーバ/sounds/jsonpdemo を開いておくだけ

- 作者: John Ferguson Smart,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/02/22
- メディア: 大型本
- 購入: 12人 クリック: 345回
- この商品を含むブログ (38件) を見る
おまけ
こんなのもあるらしいです。ウチは使ってないですが…。つなぎのヒゲの画像とBGM使ってるしアウトw
Html Audio Notifier

Jenkinsを使って継続的に静的コード解析をさせる
最近プロジェクト内でJenkinsをどう運用しているのか聞かれることがあったので書いておくことにします。
ビルドだけではもったいないので色々なことをやらせているのですが、とりあえず今回は静的コード解析について。
コード解析の設定は最初は少しだけ面倒かもしれませんが、出力されるレポートはプロジェクトの大事なインプットとなってくれます。
出力されたレポート、グラフを見て自分達の日々開発しているものをチェックしてチーム内の朝会やふりかえりでアレコレ語るのがいいんじゃないかと思います。
まずは必要なプラグインのインストール
静的コード解析
- FindBugs Plugin - コンパイル後のバイトコードを解析してバグや不具合が発生しそうなコードをチェックしてくれる
- Checkstyle Plugin - コーディング規約違反をチェックをしてくれる
- PMD Plugin - バグや不具合が発生しそうなコードをチェックしてくれる
- DRY Plugin - コピペコードのような重複したコードをチェックしてくれる
- Task Scanner Plugin - タスクスキャナーという名前ですがソースコードを任意の文字列で検索するチェックをかけることができます
- https://wiki.jenkins-ci.org/display/JENKINS/Task+Scanner+Plugin
- FIXME、TODO、XXX、deprecated、System.out.printlnとかスキャンしてます
- https://wiki.jenkins-ci.org/display/JENKINS/Task+Scanner+Plugin
- Warnings Plugin - コンパイラの警告をチェックしてくれる
- Cobertura Plugin - テストカバレッジを計測してくれる
- https://wiki.jenkins-ci.org/display/JENKINS/Cobertura+Plugin
- EmmaというプラグインもありますがCoberturaの方がレポートが見易い気がするのでこちらを利用してます
- https://wiki.jenkins-ci.org/display/JENKINS/Cobertura+Plugin



ビルドファイル(pom.xml, build.xmlの設定)
Jenkins自身ではコード解析、結果の出力はやってくれないのでコード解析の処理自体はAnt、Mavenにやらせます。
Mavenの場合はpom.xml, Antの場合はbuild.xmlに設定します。
コード解析のプラグインを突っ込むとジョブの設定画面のヘルプで丁寧に設定方法まで教えてくれるのでMavenやAntが苦手でもなんとかなると思います。
FindBugsの場合は↓のような感じ

すべての解析ツールの設定をしておきます。(FindBugs, CheckStyle, PMD, Cobertura)
※Task Scanner Pluginは設定不要
Jenkinsのビルド実行の設定
Mavenの場合、こんな感じで設定してXMLのレポート吐かせておけばJenkinsさんが見易くレポーティングしてくれます。

以上で設定完了です。一気に設定せずにビルド結果、レポートの表示を確認しながら1つずつ追加していった方がいいと思います。
設定ができていればジョブ実行をするとJenkins上で解析結果のレポートが表示されるはずです。
自分が所属するチームでの運用例
- ジョブのトリガ
- SCMレポジトリをポーリング
- コードを修正しコミットする度にビルドとコード解析が実行される。静的コード解析をローカル環境で手動でやる とかもう戻れません。
- 通知
- 基本のメール通知、IRC通知、Chrome拡張の通知
- すぐに気付くことができれば何を利用しても良いと思う。
- ビルドの失敗が続いて通知がウザイから切るっていうのは自分的には絶対ナシ。ウザイから早いとこビルドを安定させようという流れに持っていきたい。
- Jenkins上のレポート
- 出力されたレポート内容は朝会、ふりかえりのインプットに。問題の確認、共有、日々の改善につなげる。
- コード解析ツールは便利だけど誤検知も多いことをちゃんと知った上で利用する。
まとめ的な何か
Jenkinsにビルドとユニットテストまでしかやらせてないっていう話を結構聞くので書いてみました。
そこまで自動化できているのなら次のステップの静的コード解析までやらせちゃっていいのになぁと。導入コストも低いですし。
「レガシーなのでユニットテストないからウチはCIなんて無縁だよ」っていうのもよく聞きますがユニットテストなくても
とりあえずJenkins立てて静的コード解析を継続的にかけさせるのがいいんじゃないかと思います。
CPDでどれだけコピペコードがあるのか分かりますし、FindBugs、PMD、CheckStyleでよくないコードがどれだけ含まれているのか、どんな内容なのか傾向を探れます。
自動で継続的に解析しておけば "これ以上警告が増えたら通知する" とか設定でできますし。
解析ツールの結果は常に絶対ではありませんが充分参考にはなります。
また結果が時系列にグラフになることで変化に気付くことができます。
「最近警告が減ってきているのでイイネ」とか「昨日極端に増えたけどどんな変更した?」とか。
プロジェクトやチームによりけりだとは思いますが個人的にはビルド、ユニットテスト、静的コード解析まではとりあえず導入していいんじゃないかと思います。
設定さえ頑張ればJenkinsが勝手にやってくれますし。
もっと良い方法があったら教えていただけたら嬉しいです。
")
Jenkins実践入門 ?ビルド・テスト・デプロイを自動化する技術 (WEB+DB PRESS plus)
- 作者: 佐藤聖規,和田貴久,河村雅人,米沢弘樹,山岸啓,川口耕介
- 出版社/メーカー: 技術評論社
- 発売日: 2011/11/11
- メディア: 単行本(ソフトカバー)
- 購入: 26人 クリック: 496回
- この商品を含むブログ (64件) を見る
- 作者: John Ferguson Smart,Sky株式会社玉川竜司
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/02/22
- メディア: 大型本
- 購入: 12人 クリック: 345回
- この商品を含むブログ (38件) を見る

継続的デリバリー 信頼できるソフトウェアリリースのためのビルド・テスト・デプロイメントの自動化
- 作者: David Farley,Jez Humble,和智右桂,高木正弘
- 出版社/メーカー: KADOKAWA/アスキー・メディアワークス
- 発売日: 2012/03/14
- メディア: 大型本
- 購入: 24人 クリック: 567回
- この商品を含むブログ (53件) を見る
Trac Lightning 3.1.3 (Trac 0.12.2.ja1)のテーブル情報
Trac Lightning 3.1.3 (Trac 0.12.2.ja1) でレポートのクエリを書こうと思ったんだけどテーブル定義がよくわからなかったのでメモ。
結局のところTICKETテーブルだけ知ってればどーにでもなりそうなテーブル構成だった。
レポートで参照しそうなテーブル
チケット関連

ユーザ関連

スキーマ情報の参照
sqlite3 を起動して .schema を叩く
C:\TracLight\bin\sqlite3.exe C:\TracLight\projects\trac\SampleProject\db\trac.db .schema
出力されたDDL
CREATE TABLE attachment ( type text, id text, filename text, size integer, time integer, description text, author text, ipnr text, UNIQUE (type,id,filename) ); CREATE TABLE auth_cookie ( cookie text, name text, ipnr text, time integer, UNIQUE (cookie,ipnr,name) ); CREATE TABLE cache ( id text PRIMARY KEY, generation integer ); CREATE TABLE component ( name text PRIMARY KEY, owner text, description text ); CREATE TABLE enum ( type text, name text, value text, UNIQUE (type,name) ); CREATE TABLE forum ( id integer PRIMARY KEY, name text, time integer, forum_group integer, author text, moderators text, subscribers text, subject text, description text ); CREATE TABLE forum_group ( id integer PRIMARY KEY, name text, description text ); CREATE TABLE message ( id integer PRIMARY KEY, forum integer, topic integer, replyto integer, time integer, author text, body text ); CREATE TABLE milestone ( name text PRIMARY KEY, due integer, completed integer, description text ); CREATE TABLE node_change ( repos integer, rev text, path text, node_type text, change_type text, base_path text, base_rev text, UNIQUE (repos,rev,path,change_type) ); CREATE TABLE permission ( username text, action text, UNIQUE (username,action) ); CREATE TABLE report ( id integer PRIMARY KEY, author text, title text, query text, description text ); CREATE TABLE repository ( id integer, name text, value text, UNIQUE (id,name) ); CREATE TABLE revision ( repos integer, rev text, time integer, author text, message text, UNIQUE (repos,rev) ); CREATE TABLE session ( sid text, authenticated integer, last_visit integer, UNIQUE (sid,authenticated) ); CREATE TABLE session_attribute ( sid text, authenticated integer, name text, value text, UNIQUE (sid,authenticated,name) ); CREATE TABLE system ( name text PRIMARY KEY, value text ); CREATE TABLE ticket ( id integer PRIMARY KEY, type text, time integer, changetime integer, component text, severity text, priority text, owner text, reporter text, cc text, version text, milestone text, status text, resolution text, summary text, description text, keywords text ); CREATE TABLE ticket_change ( ticket integer, time integer, author text, field text, oldvalue text, newvalue text, UNIQUE (ticket,time,field) ); CREATE TABLE ticket_custom ( ticket integer, name text, value text, UNIQUE (ticket,name) ); CREATE TABLE topic ( id integer PRIMARY KEY, forum integer, time integer, author text, subscribers text, subject text, body text , status INT DEFAULT 0 NOT NULL, priority INT DEFAULT 0 NOT NULL); CREATE TABLE version ( name text PRIMARY KEY, time integer, description text ); CREATE TABLE wiki ( name text, version integer, time integer, author text, ipnr text, text text, comment text, readonly integer, UNIQUE (name,version) ); CREATE INDEX forum_time_idx ON forum (time); CREATE INDEX message_time_idx ON message (time); CREATE INDEX node_change_repos_rev_idx ON node_change (repos,rev); CREATE INDEX revision_repos_time_idx ON revision (repos,time); CREATE INDEX session_authenticated_idx ON session (authenticated); CREATE INDEX session_last_visit_idx ON session (last_visit); CREATE INDEX ticket_change_ticket_idx ON ticket_change (ticket); CREATE INDEX ticket_change_time_idx ON ticket_change (time); CREATE INDEX ticket_status_idx ON ticket (status); CREATE INDEX ticket_time_idx ON ticket (time); CREATE INDEX wiki_time_idx ON wiki (time);
Selenium WebDriver + Excelファイル でデータ駆動型テスト
前回の続きです。
Selenium WebDriverのテストケースを試験的に運用してみたのですが、各画面の入力項目や期待値があるため、通常よりも扱うパラメータが多くなってしまい、テストケースの管理がしづらくなったり、シナリオテストのコードの見通しが悪くなったりしてしまいました。
そこで JUnit Parameterized と XLSBeans を組み合わせてパラメータをExcelファイルで管理し、データ駆動型テスト(異なるテストパスでデータを変更できるテスト)をしてみたところ結構イイ感じだったので書いておきます。
JUnit Parameterizedとは?
@Parametersアノテーションを記述したメソッドでテストデータの設定をし、テストデータの数だけテストケースを繰り返し実行してくれる機能です。
テストケースの内容を変えずにパラメータのみを変更して繰り返しテストを実行したい場合に便利です。
XLSBeansとは?
以下サンプル - Amazonの商品検索をするテストケース
WebDriverで以下の動作をするテストケースを作成します。
- ブラウザを起動
- Amazonトップ画面を開く
- 検索カテゴリーを選択
- 検索テキストを入力
- Goボタンを押下
- 検索結果画面が表示
- 検索結果一覧画面に期待する商品名が表示されるか検証
入力値となる検索カテゴリー、検索テキスト、期待する検索結果はJavaのテストクラスではなくExcelファイルのテーブルに記述し、テストデータとテストシナリオを分離します。
ExcelファイルとマッピングするBeanクラスの作成
以下のようなExcelファイルを用意します。
ファイル名:Test.xls シート名:Test

ExcelのテーブルとマッピングするBeanクラスは以下2つのクラスファイルです。
アノテーションでシート名、カラム名を指定でき、Publicフィールドもサポートしているのでとてもシンプル。
@Sheet(name="Test") public class TestSheet { @HorizontalRecords(tableLabel="テストケース一覧", recordClass=TestData.class) public List<TestData> testDataList; } public class TestData { @Column(columnName="TestNo") public String testNo; @Column(columnName="カテゴリー") public String category; @Column(columnName="検索ワード") public String searchText; @Column(columnName="期待する検索結果") public String searchResult; }
JUnitのテストケースを作成
@RunWith(Parameterized.class) public class ExcelTest { /** WebDriver */ private static WebDriver driver; /** テスト用パラメータ Excelの1レコードに該当 */ private TestData testData; @BeforeClass public static void setUpBeforeClass() throws Exception { driver = new FirefoxDriver(); } @AfterClass public static void tearDownAfterClass() throws Exception { driver.quit(); } public ExcelTest(TestData testData) { this.testData = testData; } @Parameters public static List<TestData[]> data() throws Exception { // Excelファイルの読み込み TestSheet sheet = new XLSBeans().load( new FileInputStream("Test.xls"), TestSheet.class); // Parametersの設定 List<TestData[]> list = new ArrayList<TestData[]>(); for (TestData testData : sheet.testDataList) { list.add(new TestData[] {testData}); } return list; } /** * テストケース * Excelファイルのレコード数だけ繰り返し実行される * * @throws Exception */ @Test public void Amazon検索() throws Exception { // 初期表示するページ driver.get("http://www.amazon.co.jp/"); // 検索カテゴリ、テキストの入力 new Select(driver.findElement(By.id("searchDropdownBox"))).selectByVisibleText(testData.category); driver.findElement(By.id("twotabsearchtextbox")).sendKeys(testData.searchText); // Goボタン押下 driver.findElement(By.id("navGoButton")).click(); // 検索結果を検証 assertThat(testData.testNo, driver.getPageSource(), is(containsString(testData.searchResult))); } }
感想
XLSBeansとJUnit Parameterizedの組み合わせはExcelファイルの読み込み処理がとてもシンプルで導入しやすいため気に入ってます。
またテストデータがExcelファイルとなるのでテストケースのパラメータが一覧で管理しやすく、テスト内容の説明や意図なども合わせて記載できます。
テストケースのシナリオとテストデータが分離されるのでテストデータの確認や修正はExcelファイルだけで済みますし、テストケースのシナリオにはゴテゴテとパラメータが記述されないのでスッキリします。
サンプルで紹介したテストケースは入力パラメータや期待値の数が少ないので分かりにくいかもしれませんが、業務系アプリの場合 入力値は結構な数になってしまうことが多いので管理 保守面のメリットは大きいと思います。
自分はExcelファイルからソースコードを生成するのはあまり好きではないのですが、こういうExcelの利用の仕方は悪くないかなーと思っています。
Selenium WebDriver を利用して Webアプリケーションのテストをしてみる
以前から気になっていた Selenium WebDriver を使ってWebアプリの自動テストを試してみたので忘れないうちにメモ。
WebDriverに惹かれたのは以下の理由
- ブラウザの操作がJavaで簡単に書ける(学習コストが低い)
- 記述するコードが簡潔で分かりやすい(コードのメンテナンスがしやすい)
- JUnitからも実行できる(Jenkinsから実行して自動化したり)
- ブラウザのスクリーンショットが撮れる(エビデンス作成)
導入準備
ここから Selenium Client Drivers(Java) をダウンロードしてjarにクラスパスを通すだけ。
Mavenを利用する場合、pom.xmlに selenium-java を追加するだけでOKです。
ブラウザ操作の機能のみを利用するだけなら selenium-htmlunit-driver は不要なのでexclusionを指定しておくと余計な依存jarを減らせます。
<dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>2.5.0</version> <scope>test</scope> <exclusions> <exclusion> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-htmlunit-driver</artifactId> </exclusion> </exclusions> </dependency>
さっそくWebDriverを利用してブラウザを操作する
Seleniumの本家ドキュメントに載っているサンプルです。お手軽。コードを見れば処理の内容もなんとなくわかります。
実行するとFirefoxが起動し、ブラウザの操作が自動でおこなわれます。
public class Main { public static void main(String[] args) { // ブラウザ(Firefox)を起動 WebDriver driver = new FirefoxDriver(); // URLを開く driver.get("http://www.google.co.jp"); // name が "q" の要素を取得 WebElement element = driver.findElement(By.name("q")); // 文字をタイプ element.sendKeys("selenium"); // submit element.submit(); // ブラウザを閉じる driver.quit(); } }
JUnitからWebDriverを利用する
WebDriverはJUnit上でも問題なく動作します。
以下のコードはJUnitのBeforeClassを利用しテスト前処理にブラウザの起動処理を入れています。
その後テストメソッドの中で Yahoo!のTOP画面を開き、検索フィールドに『selenium』とタイプし、検索ボタンを押下しています。
テスト後の後処理はAfterClassを利用しブラウザを閉じています。
(Googleで検索をおこなうと検索フィールドにタイプした瞬間に検索結果画面が表示されてしまうので動作が分かりにくいと思ったので…。)
public class YahooSearchTest { private static WebDriver driver; @BeforeClass public static void setUpBeforeClass() throws Exception { driver = new FirefoxDriver(); // driver = new InternetExplorerDriver(); // driver = new ChromeDriver( // new ChromeDriverService.Builder() // .usingChromeDriverExecutable(new File("resources\\chromedriver.exe")) // .usingAnyFreePort() // .build()); } @AfterClass public static void tearDownAfterClass() throws Exception { driver.quit(); } @Test public void Yahoo検索() throws Exception { driver.get("http://www.yahoo.co.jp"); driver.findElement(By.name("p")).sendKeys("selenium"); driver.findElement(By.id("srchbtn")).click(); assertThat(driver.getTitle(), is("「selenium」の検索結果 - Yahoo!検索")); }
起動するブラウザを変更するには最初に生成しているDriverクラスを変更するだけです。簡単。
ただしChromeを利用する場合は以下のURLから chromedriver.exe をダウンロードし、上記サンプルのようにusingChromeDriverExecutableメソッドでexeファイルを指定する必要があります。
スクリーンショットの保存
スクリーンショットを保存するには TakesScreenshotインターフェース のgetScreenshotAsメソッドを実行すれば良いみたいです。
InternetExplolerDriverもFirefoxDriver、ChromeDriverもTakesScreenshotの実装クラスになっているためスクリーンショットの保存が可能です。
private void saveScreenshot(File saveFile){ try { if(driver instanceof TakesScreenshot) { File tmpFile = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE); FileHandler.copy(tmpFile, saveFile); } } catch(Exception e) { throw new RuntimeException(e); } }
要素を読み込むまで待機する処理
Ajaxなどの処理でJavaScriptからDOMを更新している場合は待機処理を入れないとうまく動作しない場合があったりしたので
指定したエレメントが表示されるまでの待機処理メソッドも作っておいたほうが良いです。
private void waitForElementToLoad(final By locator, int timeOutInSeconds) { new WebDriverWait(driver, timeOutInSeconds).until(new ExpectedCondition<Boolean>() { public Boolean apply(WebDriver driver) { return driver.findElement(locator).isDisplayed(); } }); }
ブラウザの操作処理 - クリック処理、文字のタイプ処理、プルダウンの選択処理
本家サイトにも載っているのですがよく使う操作をメソッドにまとめておくと便利。
/** * クリック処理 * * @param locator */ public void click(By locator) { driver.findElement(locator).click(); } /** * フォームのサブミット処理 * * @param locator */ public void submit(By locator) { driver.findElement(locator).submit(); } /** * テキストフィールドの入力処理 * * @param locator * @param text */ public void type(By locator, String text) { WebElement element = driver.findElement(locator); element.sendKeys(text); } /** * プルダウンの選択処理 * * @param locator * @param label */ public void select(By locator, String label) { Select element = new Select(driver.findElement(locator)); element.selectByVisibleText(label); } /** * sleep処理 * * @param millis */ public void sleep(long millis) { try { Thread.sleep(millis); } catch (InterruptedException e) { throw new RuntimeException(e); } }